本文共 5121 字,大约阅读时间需要 17 分钟。
目录
当爬取的数据已经被存放在 Items 以后,如果 Spider(爬虫) 解析完 Response(响应结果),Items 就会传递到 Item Pipeline(项目管道) 中,然后在 Item Pipeline 中创建用于处理数据的类,这个类就是项目管道组件,通过执行一连串的处理即可实现数据的清洗、存储等工作。
1. 项目管道的核心方法
Item Pipeline(项目管道)的典型用途如下:
- 清洗 HTML 数据。
- 验证抓取的数据(检查项目是否包含某些字段)。
- 检查重复项(并将其删除)。
- 将爬取的结果存储在数据库中。
在编写自定义 Item Pipeline 时,可以实现以下几个方法:
- process_item():该方法是在自定义 Item Pipeline 时,所必须实现的方法。该方法中需要提供两个参数,参数的具体含义如下:
- item 参数为 Item 对象(被处理的 Item)或 字典。
- spider 参数为 Spider 对象(爬取信息的爬虫)。
- open_spider():该方法是在开启爬虫时被调用的,所以在这个方法中可以进行初始化操作,其中 spider 参数就是被开启的 Spider (爬虫)对象。
- close_spider():该方法与上一方法相反,是在关闭爬虫时被调用的,在这个方法中可以进行一些收尾工作,其中 spider 参数就是被关闭的 Spider(爬虫)对象。
- from_crawler():该方法为类方法,需要使用 @classmethod 进行标识,在调用该方法时需要通过参数 cls 创建实例对象,最后需要返回这个实例对象。通过 crawler 参数可以获取 Scrapy 所有的核心组件,例如配置信息等。
2. 爬取京东数据并存储至 MySQL 数据库
了解 Item Pipeline(项目管道)的作用后,接下来便可以将爬取的数据信息通过 Item Pipeline 存储到数据库中,这里以爬取京东图书排行榜信息为例,将爬取的数据信息存储至 MySQL 数据库当中。实现的具体步骤如下:
(1) 安装并调试 MySQL 数据库,然后通过 Navicat for MySQL 创建数据库名称 jd_data,如下图所示:
 (2) 在
(2) 在 jd_data 数据库当中创建名称为 ranking 的数据表,如下图所示: 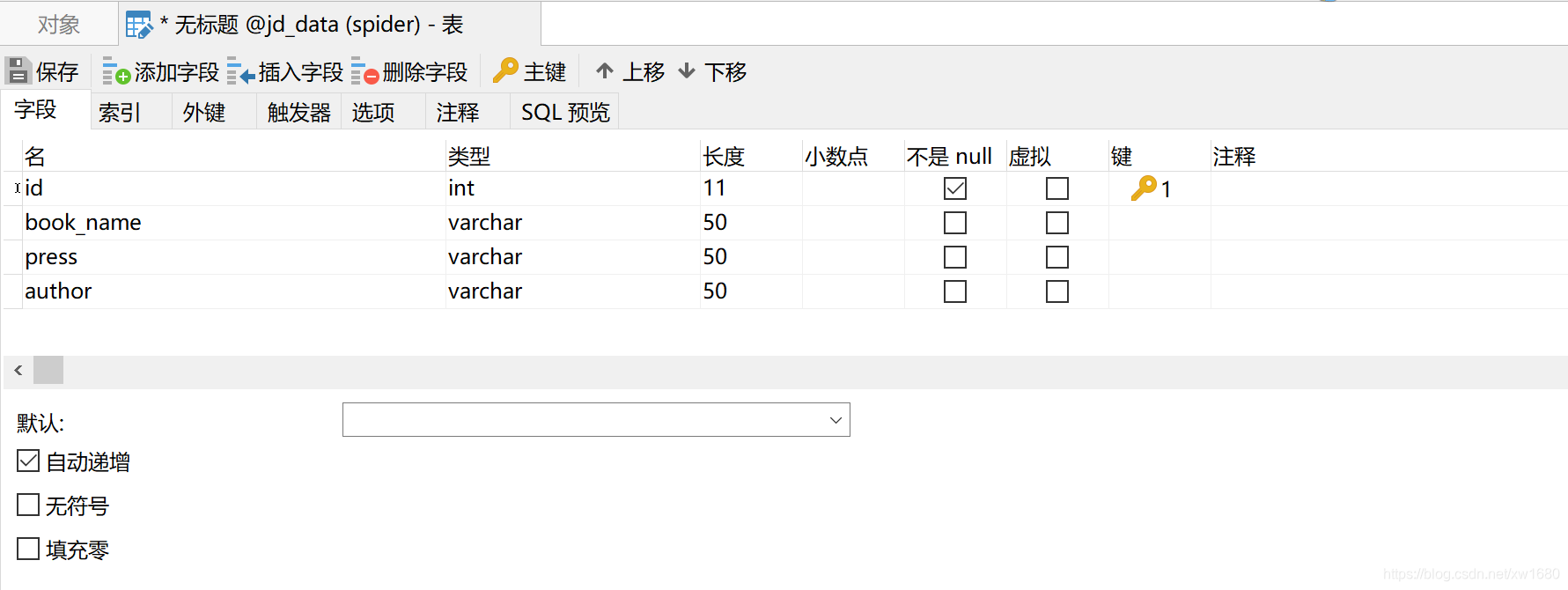 (3) 通过谷歌浏览器打开京东图书排行榜网页地址
(3) 通过谷歌浏览器打开京东图书排行榜网页地址 https://book.jd.com/booktop/0-0-0.html?category=3287-0-0-0-10001-1
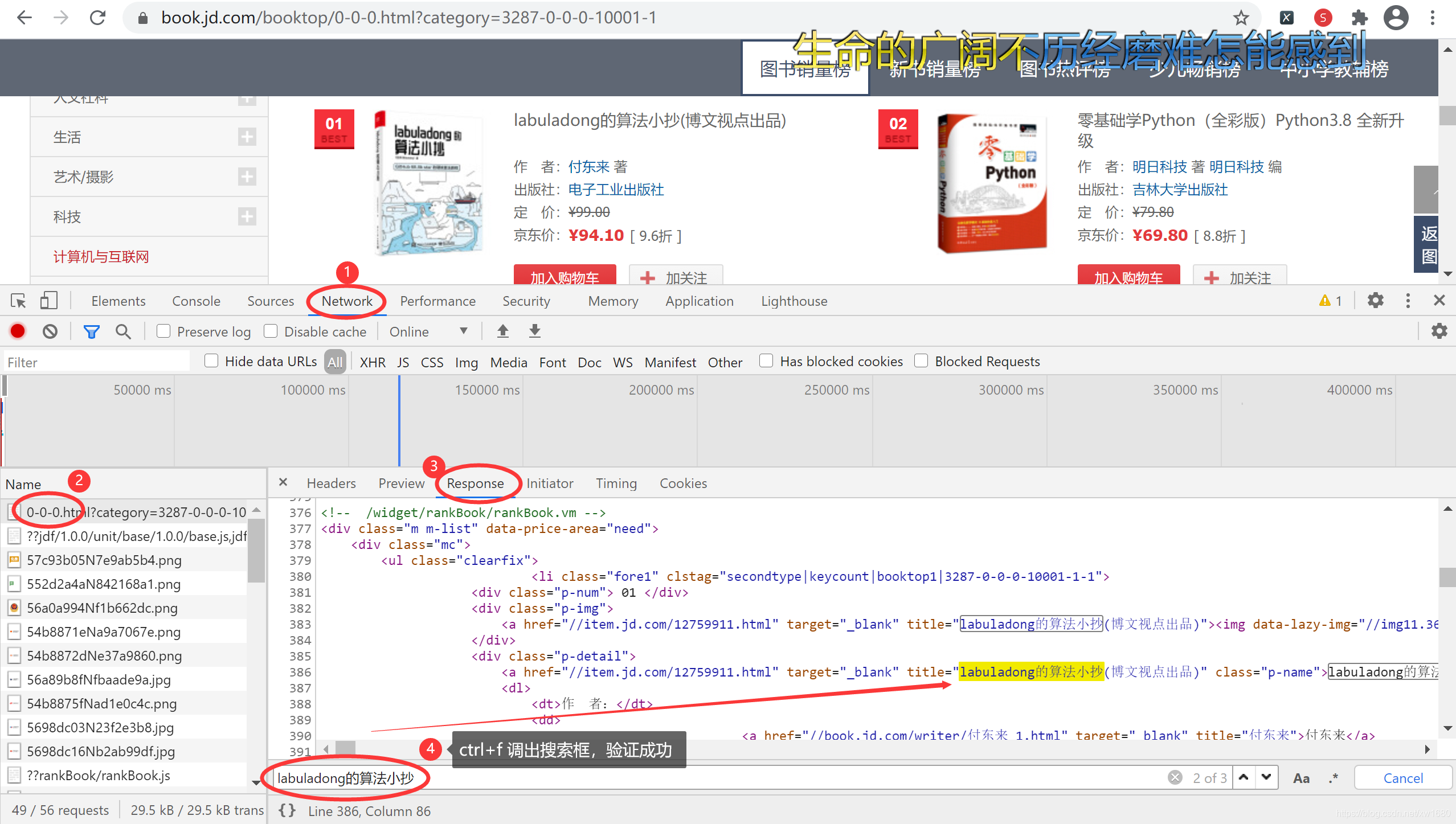
验证成功之后,按 <F12> 快捷键或者鼠标右键打开浏览器的开发者工具,首先选择 Network 选项,然后找到该页面的 URL,单击,切换到 Response 选项卡,验证我们要抓取的数据是否在响应当中,如果不是我们需要重新找请求页面数据的 URL。
 接着选择 Elements 选项,然后单击左上角的箭头图标,选择网页中需要提取的数据,最后定位数据位置。如下图所示:
接着选择 Elements 选项,然后单击左上角的箭头图标,选择网页中需要提取的数据,最后定位数据位置。如下图所示: 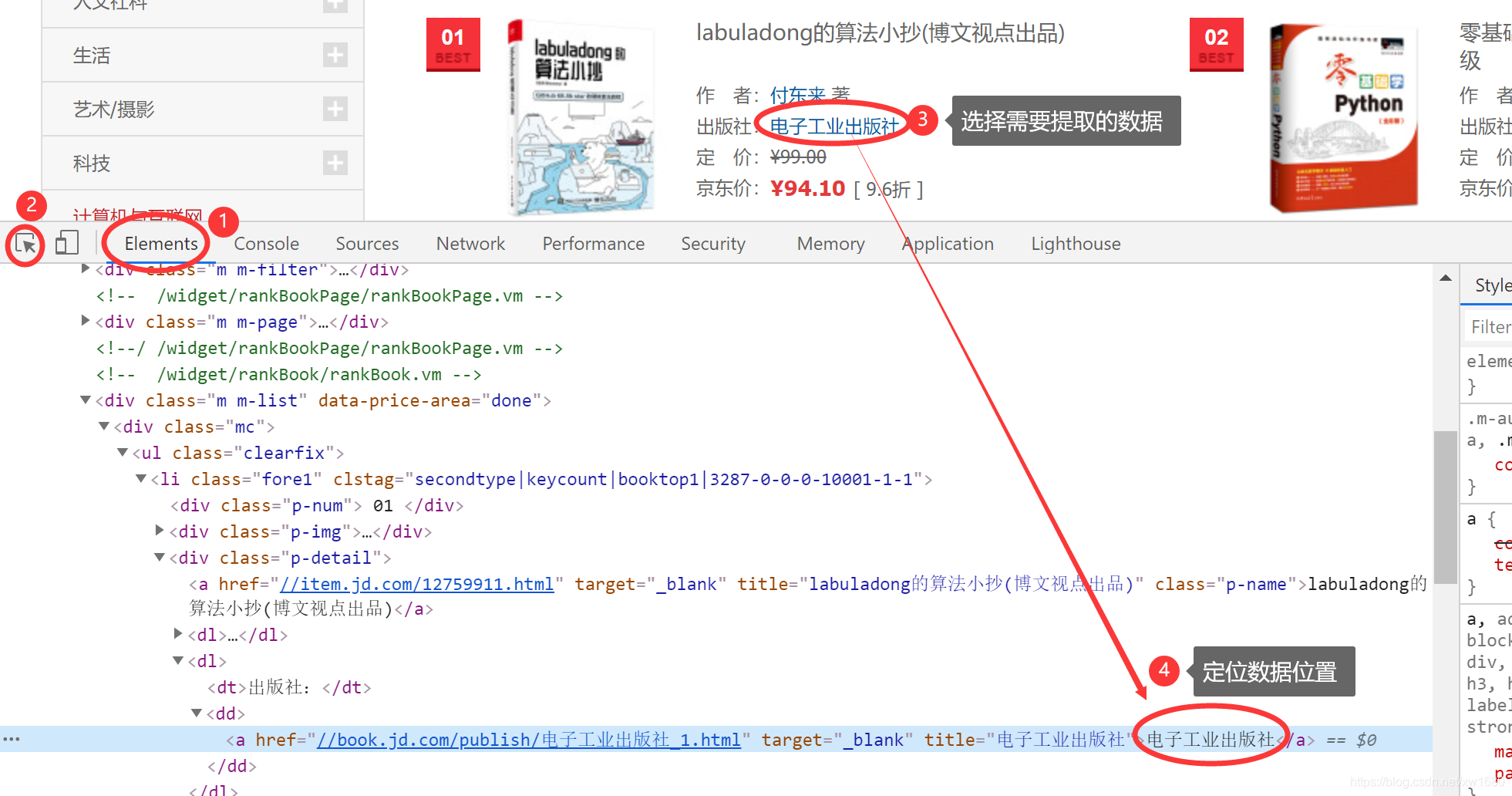 根据以上定位数据的步骤依次获取书名、作者、出版社所对应的数据。 (4) 确定了数据在 HTML 代码中的位置,接下来在命令行窗口中通过以下命令创建项目文件夹及爬虫文件:
根据以上定位数据的步骤依次获取书名、作者、出版社所对应的数据。 (4) 确定了数据在 HTML 代码中的位置,接下来在命令行窗口中通过以下命令创建项目文件夹及爬虫文件: 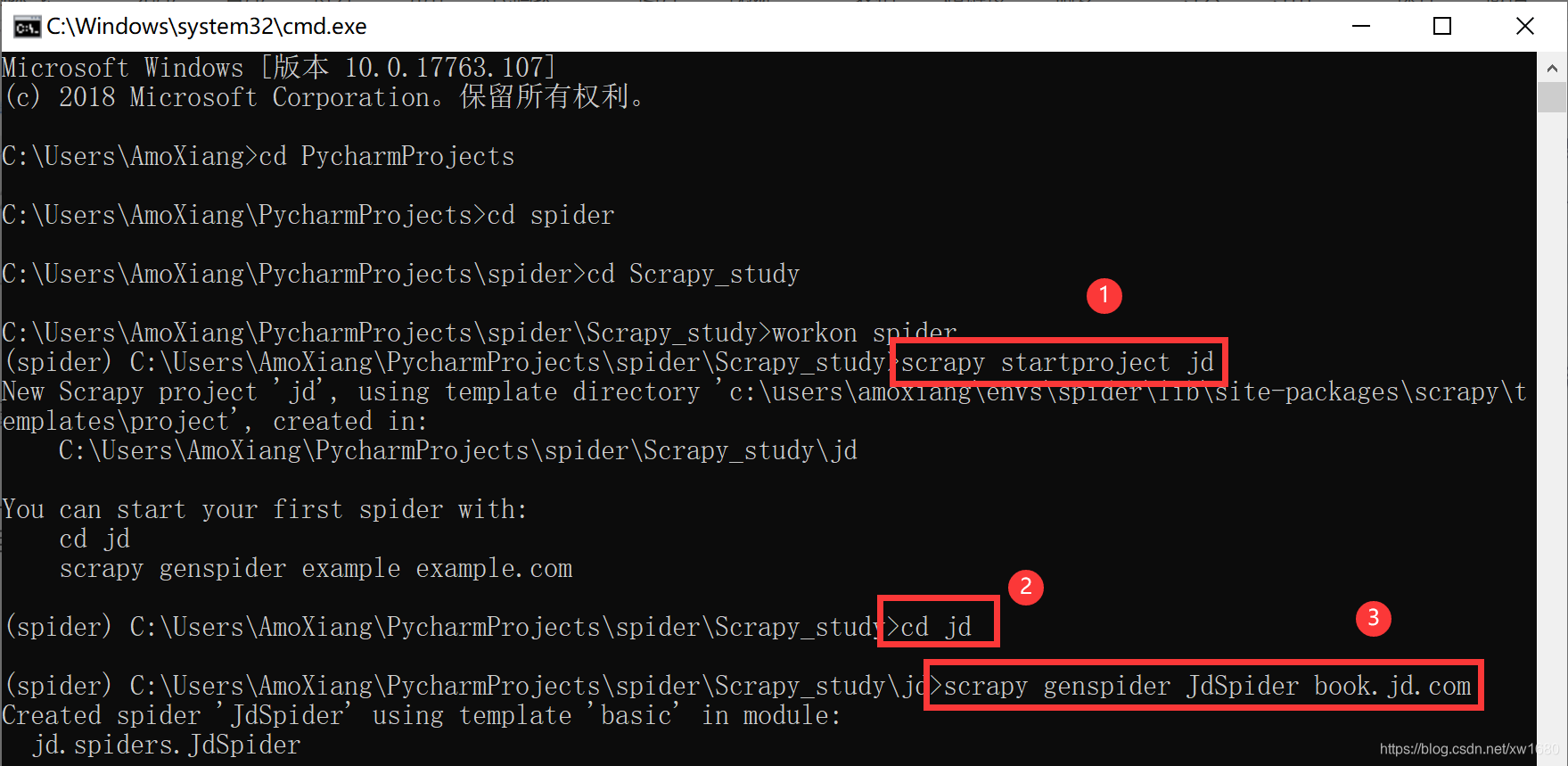 接着用开发工具 Pycharm 打开项目,完整的项目结构如图所示:
接着用开发工具 Pycharm 打开项目,完整的项目结构如图所示:  (5) 打开项目文件夹结构中的 items.py 文件,在该文件中定义 Item,代码如下:
(5) 打开项目文件夹结构中的 items.py 文件,在该文件中定义 Item,代码如下: import scrapyclass JdItem(scrapy.Item): book_name = scrapy.Field() # 保存图书名称 author = scrapy.Field() # 保存作者 press = scrapy.Field() # 保存出版社
(6) 打开 JdSpider.py 爬虫文件,在该文件中重写 start_requests 方法,用于实现对京东图书排行榜的网络请求。以及在该方法的下面,重写 parse() 方法,用于实现网页数据的抓取,然后将爬取的数据添加至 Item 对象中。代码如下:
import scrapyfrom jd.items import JdItemclass JdspiderSpider(scrapy.Spider): name = 'JdSpider' allowed_domains = ['book.jd.com'] start_urls = ['http://book.jd.com/'] def start_requests(self): # 需要访问的地址 url = "https://book.jd.com/booktop/0-0-0.html?category=3287-0-0-0-10001-1" yield scrapy.Request(url=url, callback=self.parse) # 发送网络请求 def parse(self, response): li_list = response.xpath('//div[@class="m m-list"]/div/ul/li') for li in li_list: # 获取图书名称 book_name = li.xpath('div[@class="p-detail"]/a/text()').extract_first() # 获取作者 author = li.xpath('//div[@class="p-detail"]/dl[1]/dd/a[1]/text()').extract_first() # 获取出版社 press = li.xpath('//div[@class="p-detail"]/dl[2]/dd/a[1]/text()').extract_first() item = JdItem() # 创建Item对象 # 将数据添加至Item对象 item['book_name'] = book_name item['author'] = author item['press'] = press yield item (8) 使用 Pycharm 运行当前爬虫,如下:
 启动爬虫后,控制台将打印 Item 对象内所有爬取的信息。 (9) 确认数据已经爬取,接下来需要在项目管道中将数据存储至 MySQL 数据库当中,首先打开 pipelines.py 文件,在该文件中首先导入 PyMySQL 数据库操作模块,然后通过 init() 方法初始化数据库连接参数、重写from_crawler() 方法、open_spider()方法、close_spider()方法、process_item()方法 等操作。代码如下:
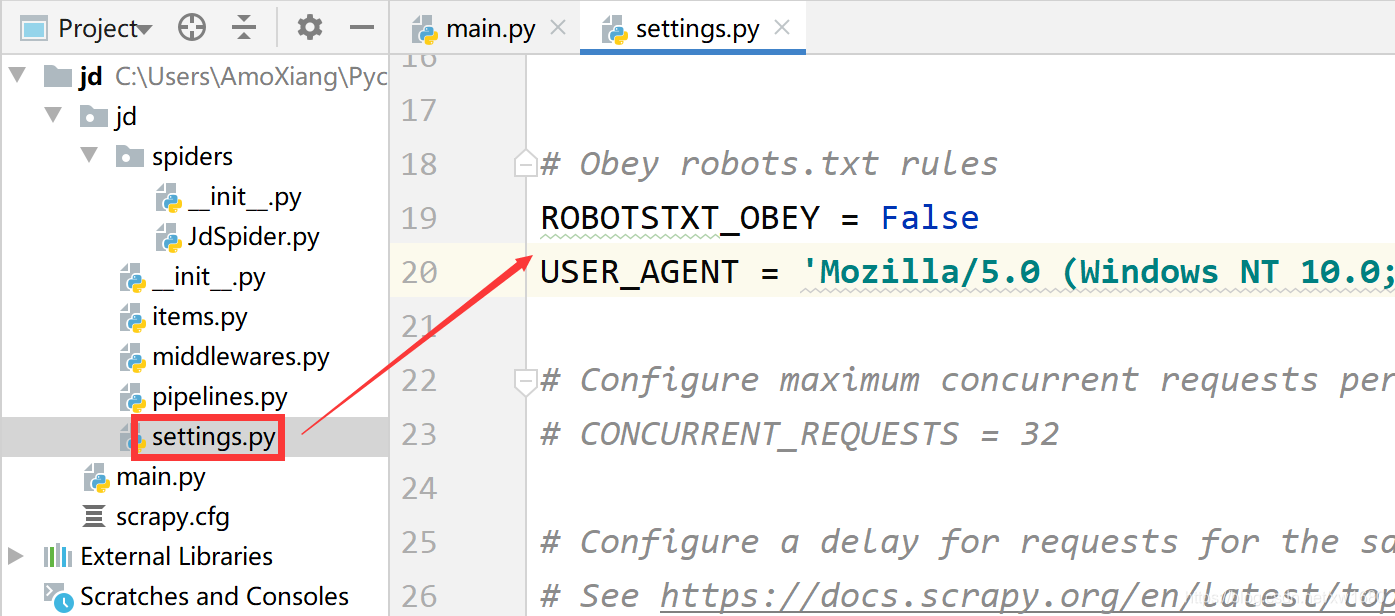
启动爬虫后,控制台将打印 Item 对象内所有爬取的信息。 (9) 确认数据已经爬取,接下来需要在项目管道中将数据存储至 MySQL 数据库当中,首先打开 pipelines.py 文件,在该文件中首先导入 PyMySQL 数据库操作模块,然后通过 init() 方法初始化数据库连接参数、重写from_crawler() 方法、open_spider()方法、close_spider()方法、process_item()方法 等操作。代码如下: import pymysql # 导入数据库连接PyMySQL模块class JdPipeline: # 初始化数据库参数 def __init__(self, host, database, user, password, port): self.host = host self.database = database self.user = user self.password = password self.port = port @classmethod def from_crawler(cls, crawler): # 返回cls()实例对象,其中包含通过crawler获取的配置文件中的数据库参数 return cls( host=crawler.settings.get('SQL_HOST'), database=crawler.settings.get('SQL_DATABASE'), user=crawler.settings.get('SQL_USER'), password=crawler.settings.get('SQL_PASSWORD'), port=crawler.settings.get('SQL_PORT'), ) # 打开爬虫时调用 def open_spider(self, spider): # 数据库连接 self.db = pymysql.connect(self.host, self.user, self.password, self.database, self.port, charset="utf8") self.cursor = self.db.cursor() # 创建游标 # 关闭爬虫时调用 def close_spider(self, spider): self.db.close() def process_item(self, item, spider): data = dict(item) # 将Item转换成字典类型 # SQL语句 sql = "insert into ranking(book_name,press,author) values (%s,%s,%s)" # 执行数据的插入 self.cursor.execute(sql, (data['book_name'], data['press'], data['author'])) self.db.commit() # 提交 return item # 返回Item (10) 打开 settings.py 文件,在该文件中找到激活项目管道的代码并解除注释状态,然后设置数据库信息的变量。代码如下:
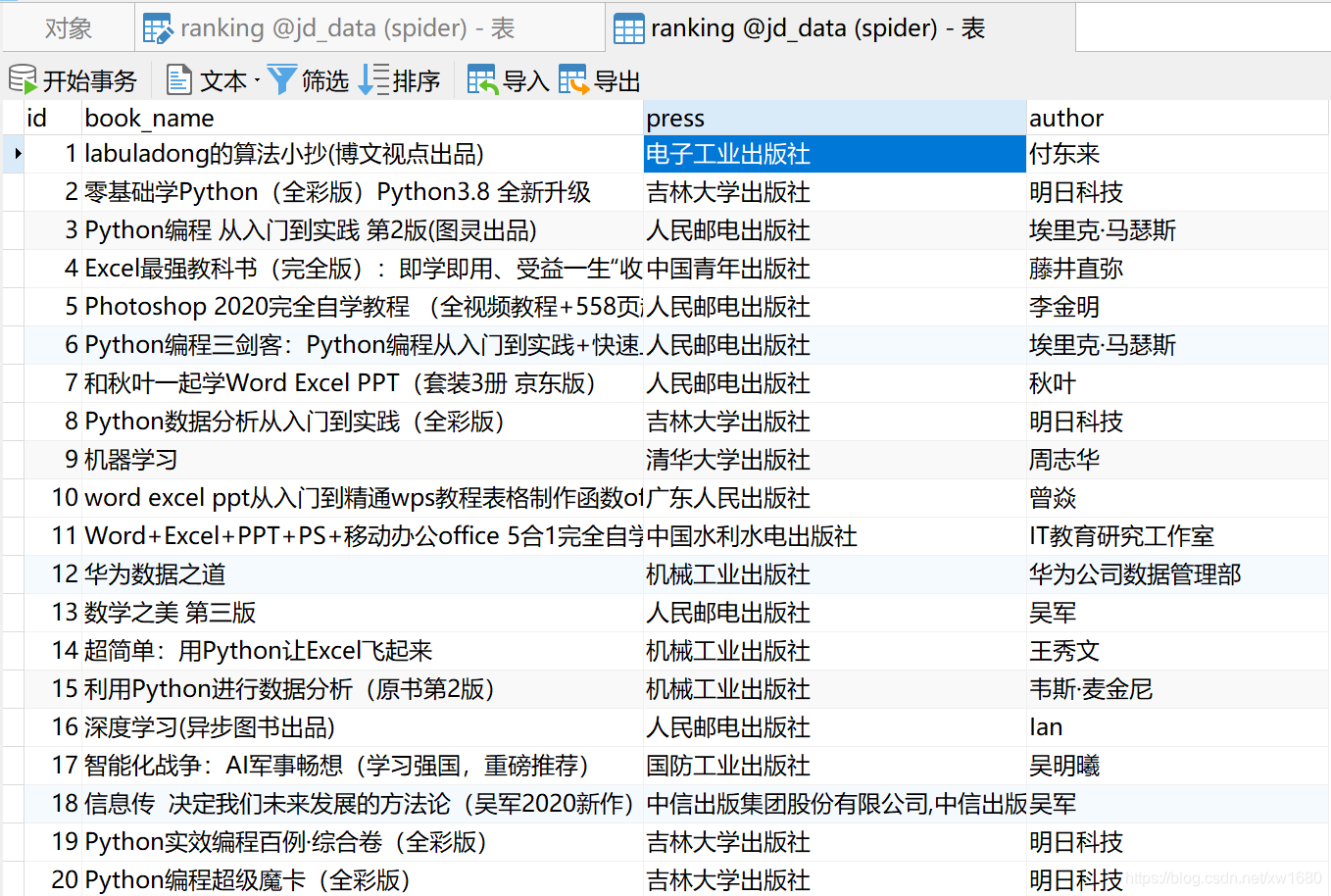
ROBOTSTXT_OBEY = FalseUSER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36'SQL_HOST = 'localhost' # 数据库地址SQL_USER = 'root' # 用户名SQL_PASSWORD = 'mysql' # 密码SQL_DATABASE = 'jd_data' # 数据库名称SQL_PORT = 3306 # 端口# 开启jd项目管道ITEM_PIPELINES = { 'jd.pipelines.JdPipeline': 300,} (11) 打开 main.py 文件,在该文件中再次启动爬虫,爬虫程序执行完毕以后,打开 ranking 数据表,将显示如下图所示的数据信息。
 至此今天的案例就到此结束了,笔者在这里声明,笔者写文章只是为了学习交流,以及让更多学习 Python 基础的读者少走一些弯路,节省时间,并不用做其他用途,如有侵权,联系博主删除即可。感谢您阅读本篇博文,希望本文能成为您编程路上的领航者。祝您阅读愉快!
至此今天的案例就到此结束了,笔者在这里声明,笔者写文章只是为了学习交流,以及让更多学习 Python 基础的读者少走一些弯路,节省时间,并不用做其他用途,如有侵权,联系博主删除即可。感谢您阅读本篇博文,希望本文能成为您编程路上的领航者。祝您阅读愉快! 
好书不厌读百回,熟读课思子自知。而我想要成为全场最靓的仔,就必须坚持通过学习来获取更多知识,用知识改变命运,用博客见证成长,用行动证明我在努力。
如果我的博客对你有帮助、如果你喜欢我的博客内容,请点赞、评论、收藏一键三连哦!听说点赞的人运气不会太差,每一天都会元气满满呦!如果实在要白嫖的话,那祝你开心每一天,欢迎常来我博客看看。 编码不易,大家的支持就是我坚持下去的动力。点赞后不要忘了关注我哦!
转载地址:http://ldjk.baihongyu.com/